Xcdat: Fast compressed trie dictionary library
![]()
Xcdat is a C++17 header-only library of a fast compressed string dictionary based on an improved double-array trie structure described in the paper: Compressed double-array tries for string dictionaries supporting fast lookup, Knowledge and Information Systems, 2017, available here.
Table of contents
- Features
- Build instructions
- Command line tools
- Sample usage
- API
- Performance
- Licensing
- Todo
- References
Features
- Compressed string dictionary. Xcdat implements a (static) compressed string dictioanry that stores a set of strings (or keywords) in a compressed space while supporting several search operations [1,2]. For example, Xcdat can store an entire set of English Wikipedia titles at half the size of the raw data. (See Performance)
- Fast and compact data structure. Xcdat employs the double-array trie [3] known as the fastest trie implementation. However, the double-array trie resorts to many pointers and consumes a large amount of memory. To address this, Xcdat applies the XCDA method [2] that represents the double-array trie in a compressed format while maintaining the fast searches.
- Cache efficiency. Xcdat employs a minimal-prefix trie [4] that replaces redundant trie nodes into strings to reduce random access and to improve locality of references.
- Dictionary encoding. Xcdat maps
Ndistinct keywords into unique IDs from[0,N-1], and supports the two symmetric operations:lookupreturns the ID corresponding to a given keyword;decodereturns the keyword associated with a given ID. The mapping is so-called dictionary encoding (or domain encoding) and is fundamental in many DB applications as described by Martínez-Prieto et al [1] or Müller et al. [5]. - Prefix search operations. Xcdat supports prefix search operations realized by trie search algorithms:
prefix_searchreturns all the keywords contained as prefixes of a given string;predictive searchreturns all the keywords starting with a given string. These will be useful in many NLP applications such as auto completions [6], stemmed searches [7], or input method editors [8]. - 64-bit support. As mentioned before, since the double array is a pointer-based data structure, most double-array libraries use 32-bit pointers to reduce memory consumption, resulting in limiting the scale of the input dataset. On the other hand, the XCDA method allows Xcdat to represent 64-bit pointers without sacrificing memory efficiency.
- Binary key support. In normal mode, Xcdat will use the
\0character as an end marker for each keyword. However, if the dataset include\0characters, it will use bit flags instead of end markers, allowing the dataset to consist of binary keywords. - Memory mapping. Xcdat supports memory mapping, allowing data to be deserialized quickly without loading it into memory. Of course, deserialization by the loading is also supported.
- Header only. The library consists only of header files, and you can easily install it.
- Python binding. You can use Xcdat in Python3 via pybind11. (Visit the directory pybind)
Build instructions
You can download, compile, and install Xcdat with the following commands.
$ git clone https://github.com/kampersanda/xcdat.git
$ cd xcdat
$ mkdir build
$ cd build
$ cmake ..
$ make -j
$ make install
Or, since this library consists only of header files, you can easily install it by passing the include path to the directory include.
Requirements
You need to install a modern C++17 ready compiler such as g++ >= 7.0 or clang >= 4.0. For the build system, you need to install CMake >= 3.0 to compile the library.
The library requires that std::uint64_t exists. (This is true for nearly any target, even 32-bit ones.) The code has been tested only on Mac OS X and Linux. That is, this library considers only UNIX-compatible OS.
Python binding
Xcdat supports the Python binding via pybind11. The description can be found in the directory pybind.
Command line tools
Xcdat provides command line tools to build the dictionary and perform searches, which are inspired by marisa-trie. All the tools will print the command line options by specifying the parameter -h.
The tools employ the external libraries cmd_line_parser, mm_file, and tinyformat, which are contained in the repository.
xcdat_build
It builds the trie dictionary from a given dataset consisting of keywords separated by newlines. The following command builds the trie dictionary from dataset enwiki-titles.txt and writes the dictionary into file dic.bin.
$ xcdat_build enwiki-titles.txt dic.bin
Number of keys: 15955763
Number of trie nodes: 36439320
Number of DA units: 36515840
Memory usage in bytes: 1.64104e+08
Memory usage in MiB: 156.502
xcdat_lookup
It tests the lookup operation for a given dictionary. Given a query string via stdin, it prints the associated ID if found, or -1 otherwise.
$ xcdat_lookup dic.bin
Algorithm
1255938 Algorithm
Double_Array
-1 Double_Array
xcdat_decode
It tests the decode operation for a given dictionary. Given a query ID via stdin, it prints the corresponding keyword if the ID is in the range [0,N-1], where N is the number of stored keywords.
$ xcdat_decode dic.bin
1255938
1255938 Algorithm
xcdat_prefix_search
It tests the prefix_search operation for a given dictionary. Given a query string via stdin, it prints all the keywords contained as prefixes of a given string.
$ xcdat_prefix_search dic.bin
Algorithmic
6 found
57 A
798460 Al
1138004 Alg
1253024 Algo
1255938 Algorithm
1255931 Algorithmic
xcdat_predictive_search
It tests the predictive_search operation for a given dictionary. Given a query string via stdin, it prints the first n keywords starting with a given string, where n is one of the parameters.
$ xcdat_predictive_search dic.bin -n 3
Algorithm
263 found
1255938 Algorithm
1255944 Algorithm's_optimality
1255972 Algorithm_(C++)
xcdat_enumerate
It prints all the keywords stored in a given dictionary.
$ xcdat_enumerate dic.bin | head -3
0 !
107 !!
138 !!!
xcdat_benchmark
Xcdat provides the four dictionary types defined in xcdat.hpp. The tool measures the performances of them for a given dataset. To perform search operations, it randomly samples n queires from the dataset, where n is one of the parameters. It will help you determine the dictionary type.
$ xcdat_benchmark enwiki-titles.txt
** xcdat::trie_7_type **
Number of keys: 15955763
Memory usage in bytes: 1.70618e+08
Memory usage in MiB: 162.714
Construction time in seconds: 13.501
Lookup time in microsec/query: 0.5708
Decode time in microsec/query: 1.0846
** xcdat::trie_8_type **
Number of keys: 15955763
Memory usage in bytes: 1.64104e+08
Memory usage in MiB: 156.502
Construction time in seconds: 13.626
Lookup time in microsec/query: 0.6391
Decode time in microsec/query: 1.0531
** xcdat::trie_15_type **
Number of keys: 15955763
Memory usage in bytes: 2.05737e+08
Memory usage in MiB: 196.206
Construction time in seconds: 13.425
Lookup time in microsec/query: 0.3613
Decode time in microsec/query: 0.7044
** xcdat::trie_16_type **
Number of keys: 15955763
Memory usage in bytes: 2.15935e+08
Memory usage in MiB: 205.932
Construction time in seconds: 13.704
Lookup time in microsec/query: 0.3832
Decode time in microsec/query: 0.8362
Sample usage
sample/sample.cpp provides a sample usage.
#include <iostream>
#include <string>
#include <xcdat.hpp>
int main() {
// Dataset of keywords
std::vector<std::string> keys = {
"AirPods", "AirTag", "Mac", "MacBook", "MacBook_Air", "MacBook_Pro",
"Mac_Mini", "Mac_Pro", "iMac", "iPad", "iPhone", "iPhone_SE",
};
// The input keys must be sorted and unique (already satisfied in this case).
std::sort(keys.begin(), keys.end());
keys.erase(std::unique(keys.begin(), keys.end()), keys.end());
// The trie dictionary type from the four types
using trie_type = xcdat::trie_8_type;
// using trie_type = xcdat::trie_16_type;
// using trie_type = xcdat::trie_7_type;
// using trie_type = xcdat::trie_15_type;
// The dictionary filename
const char* tmp_filename = "dic.bin";
// Build and save the trie dictionary.
try {
const trie_type trie(keys);
xcdat::save(trie, tmp_filename);
} catch (const xcdat::exception& ex) {
std::cerr << ex.what() << std::endl;
return 1;
}
// Load the trie dictionary on memory.
const auto trie = xcdat::load<trie_type>(tmp_filename);
// Or, you can set the continuous memory block via a memory-mapped file.
// const auto trie = xcdat::mmap<trie_type>(mapped_data);
// Basic statistics
std::cout << "Number of keys: " << trie.num_keys() << std::endl;
std::cout << "Number of trie nodes: " << trie.num_nodes() << std::endl;
std::cout << "Number of DA units: " << trie.num_units() << std::endl;
std::cout << "Memory usage in bytes: " << xcdat::memory_in_bytes(trie) << std::endl;
// Lookup the ID for a query key.
{
const auto id = trie.lookup("Mac_Pro");
std::cout << "Lookup(Mac_Pro) = " << id.value_or(UINT64_MAX) << std::endl;
}
{
const auto id = trie.lookup("Google_Pixel");
std::cout << "Lookup(Google_Pixel) = " << id.value_or(UINT64_MAX) << std::endl;
}
// Decode the key for a query ID.
{
const auto dec = trie.decode(4);
std::cout << "Decode(4) = " << dec << std::endl;
}
// Common prefix search
{
std::cout << "CommonPrefixSearch(MacBook_Air) = {" << std::endl;
auto itr = trie.make_prefix_iterator("MacBook_Air");
while (itr.next()) {
std::cout << " (" << itr.decoded_view() << ", " << itr.id() << ")," << std::endl;
}
std::cout << "}" << std::endl;
}
// Predictive search
{
std::cout << "PredictiveSearch(Mac) = {" << std::endl;
auto itr = trie.make_predictive_iterator("Mac");
while (itr.next()) {
std::cout << " (" << itr.decoded_view() << ", " << itr.id() << ")," << std::endl;
}
std::cout << "}" << std::endl;
}
// Enumerate all the keys (in lexicographical order).
{
std::cout << "Enumerate() = {" << std::endl;
auto itr = trie.make_enumerative_iterator();
while (itr.next()) {
std::cout << " (" << itr.decoded_view() << ", " << itr.id() << ")," << std::endl;
}
std::cout << "}" << std::endl;
}
std::remove(tmp_filename);
return 0;
}
The output will be
Number of keys: 12
Number of trie nodes: 28
Number of DA units: 256
Memory usage in bytes: 1766
Lookup(Mac_Pro) = 7
Lookup(Google_Pixel) = 18446744073709551615
Decode(4) = MacBook_Air
CommonPrefixSearch(MacBook_Air) = {
(Mac, 1),
(MacBook, 2),
(MacBook_Air, 4),
}
PredictiveSearch(Mac) = {
(Mac, 1),
(MacBook, 2),
(MacBook_Air, 4),
(MacBook_Pro, 11),
(Mac_Mini, 5),
(Mac_Pro, 7),
}
Enumerate() = {
(AirPods, 0),
(AirTag, 3),
(Mac, 1),
(MacBook, 2),
(MacBook_Air, 4),
(MacBook_Pro, 11),
(Mac_Mini, 5),
(Mac_Pro, 7),
(iMac, 10),
(iPad, 6),
(iPhone, 8),
(iPhone_SE, 9),
}
API
Xcdat consists of only the header files and can be used by including only the header xcdat.hpp. Also, it uses namespace xcdat.
Trie dictionary types
The four specialization types of class xcdat::trie are provided in xcdat.hpp. The first two types are based on standard DACs by Brisaboa et al. [9]. The last two types are based on pointer-based DACs by Kanda et al. [2].
//! The trie type with standard DACs using 8-bit integers
using trie_8_type = trie<bc_vector_8>;
//! The trie type with standard DACs using 16-bit integers
using trie_16_type = trie<bc_vector_16>;
//! The trie type with pointer-based DACs using 7-bit integers (for the 1st layer)
using trie_7_type = trie<bc_vector_7>;
//! The trie type with pointer-based DACs using 15-bit integers (for the 1st layer)
using trie_15_type = trie<bc_vector_15>;
Trie dictionary class
The trie dictionary class provides the following functions.
//! A compressed string dictionary based on an improved double-array trie.
//! 'BcVector' is the data type of Base and Check vectors.
template <class BcVector>
class trie {
public:
//! The type identifier.
static constexpr std::uint32_t type_id;
//! Default constructor
trie() = default;
//! Default destructor
virtual ~trie() = default;
//! Copy constructor (deleted)
trie(const trie&) = delete;
//! Copy constructor (deleted)
trie& operator=(const trie&) = delete;
//! Move constructor
trie(trie&&) noexcept = default;
//! Move constructor
trie& operator=(trie&&) noexcept = default;
//! Build the trie from the input keywords, which are lexicographically sorted and unique.
//!
//! If bin_mode = false, the NULL character is used for the termination of a keyword.
//! If bin_mode = true, bit flags are used istead, and the keywords can contain NULL characters.
//! If the input keywords contain NULL characters, bin_mode will be forced to be set to true.
//!
//! The type 'Strings' and 'Strings::value_type' should be a random iterable container such as std::vector.
//! Precisely, they should support the following operations:
//! - size() returns the container size.
//! - operator[](i) accesses the i-th element.
//! - begin() returns the iterator to the beginning.
//! - end() returns the iterator to the end.
//! The type 'Strings::value_type::value_type' should be one-byte integer type such as 'char'.
template <class Strings>
trie(const Strings& keys, bool bin_mode = false);
//! Check if the binary mode.
bool bin_mode() const;
//! Get the number of stored keywords.
std::uint64_t num_keys() const;
//! Get the alphabet size.
std::uint64_t alphabet_size() const;
//! Get the maximum length of keywords.
std::uint64_t max_length() const;
//! Get the number of trie nodes.
std::uint64_t num_nodes() const;
//! Get the number of DA units.
std::uint64_t num_units() const;
//! Get the number of unused DA units.
std::uint64_t num_free_units() const;
//! Get the length of TAIL vector.
std::uint64_t tail_length() const;
//! Lookup the ID of the keyword.
std::optional<std::uint64_t> lookup(std::string_view key) const;
//! Decode the keyword associated with the ID.
std::string decode(std::uint64_t id) const;
//! Decode the keyword associated with the ID and store it in 'decoded'.
//! It can avoid reallocation of memory to store the result.
void decode(std::uint64_t id, std::string& decoded) const;
//! An iterator class for common prefix search.
//! It enumerates all the keywords contained as prefixes of a given string.
//! It should be instantiated via the function 'make_prefix_iterator'.
class prefix_iterator {
public:
prefix_iterator() = default;
//! Increment the iterator.
//! Return false if the iteration is terminated.
bool next();
//! Get the result ID.
std::uint64_t id() const;
//! Get the result keyword.
std::string decoded() const;
//! Get the reference to the result keyword.
//! Note that the referenced data will be changed in the next iteration.
std::string_view decoded_view() const;
};
//! Make the common prefix searcher for the given keyword.
prefix_iterator make_prefix_iterator(std::string_view key) const;
//! Preform common prefix search for the keyword.
void prefix_search(std::string_view key, const std::function<void(std::uint64_t, std::string_view)>& fn) const;
//! An iterator class for predictive search.
//! It enumerates all the keywords starting with a given string.
//! It should be instantiated via the function 'make_predictive_iterator'.
class predictive_iterator {
public:
predictive_iterator() = default;
//! Increment the iterator.
//! Return false if the iteration is terminated.
bool next();
//! Get the result ID.
std::uint64_t id() const;
//! Get the result keyword.
std::string decoded() const;
//! Get the reference to the result keyword.
//! Note that the referenced data will be changed in the next iteration.
std::string_view decoded_view() const;
};
//! Make the predictive searcher for the keyword.
predictive_iterator make_predictive_iterator(std::string_view key) const;
//! Preform predictive search for the keyword.
void predictive_search(std::string_view key, const std::function<void(std::uint64_t, std::string_view)>& fn) const;
//! An iterator class for enumeration.
//! It enumerates all the keywords stored in the trie.
//! It should be instantiated via the function 'make_enumerative_iterator'.
using enumerative_iterator = predictive_iterator;
//! An iterator class for enumeration.
enumerative_iterator make_enumerative_iterator() const;
//! Enumerate all the keywords and their IDs stored in the trie.
void enumerate(const std::function<void(std::uint64_t, std::string_view)>& fn) const;
//! Visit the members (commonly used for I/O).
template <class Visitor>
void visit(Visitor& visitor);
};
I/O utilities
xcdat.hpp provides some functions for handling I/O operations.
//! Set the continuous memory block to a new trie instance (for a memory-mapped file).
template <class Trie>
Trie mmap(const char* address);
//! Load the trie dictionary from the file.
template <class Trie>
Trie load(const std::string& filepath);
//! Save the trie dictionary to the file and returns the file size in bytes.
//! The identifier of the trie type will be written in the first 4 bytes.
template <class Trie>
std::uint64_t save(const Trie& idx, const std::string& filepath);
//! Get the dictionary size in bytes.
template <class Trie>
std::uint64_t memory_in_bytes(const Trie& idx);
//! Get the identifier of the trie type embedded by the function 'save'.
//! The identifier corresponds to trie::type_id and will be used to detect the trie type.
std::uint32_t get_type_id(const std::string& filepath);
Exception class
If an error occurs in a construction or I/O operation, Xcdat will throw an instance of xcdat::exception as a runtime error.
class exception : public std::exception {
public:
//! Get the error massage.
const char* what() const throw() override;
};
Performance
We compared the performance of Xcdat with those of other selected dictionary libraries written in C++.
Implementations
- Our compressed double-array tries [2]
- Other double-array tries
- darts: Double-array trie [3].
- darts-clone: Compact double-array trie [4].
- cedar: Dynamic double-array reduced trie [10,11]
- cedarpp: Dynamic double-array prefix trie [10,11]
- dastrie: Compact double-array prefix trie [4]
- Succinct tries
- Tessil’s string containers
- hat-trie: HAT-trie [16]
- array-hash: Array hashing [17]
Environments
- Machine: MacBook Pro (13-inch, 2019)
- OS: macOS Catalina (version 10.15)
- Processor: 2.4 GHz Quad-Core Intel Core i5
- Memory: 16 GB 2133 MHz LPDDR3
- Compiler: AppleClang (version 12.0.0)
- Optimization flags:
-O3 -march=native
Datasets
- Natural language corpus
- IPA: 325,871 different Japanese words from IPAdic (3.7 MiB, 11.9 bytes/key)
- Wiki: 14,130,439 different English Wikipedia titles on 2018-09-20 (285 MiB, 21.2 bytes/key)
- Askitis’s datasets
- Distinct: 28,772,169 different english words (290 MiB, 10.6 bytes/key)
- Url: 1,289,458 different URL strings (44 MiB, 36.2 bytes/key)
Approach
We constructed a dictionary from a dataset and measured the elapsed time. The dynamic dictionaries, Cedar and Tessil’s containers, were constructed by inserting sorted keywords. Each keyword is associated with a unique ID of a 4-byte integer. Since all the libraries support serialization of the data structure, we measured the output file size as the memory usage.
The time to lookup IDs from keywords was measured for 1,000 query keywords randomly sampled from each dataset. Also, for some libraries supporting to decode keywords from IDs, the time was measured for the 1,000 IDs corresponding to the query keywords. We took the best result of 10 runs.
The code of the benchmark can be found here.
Results
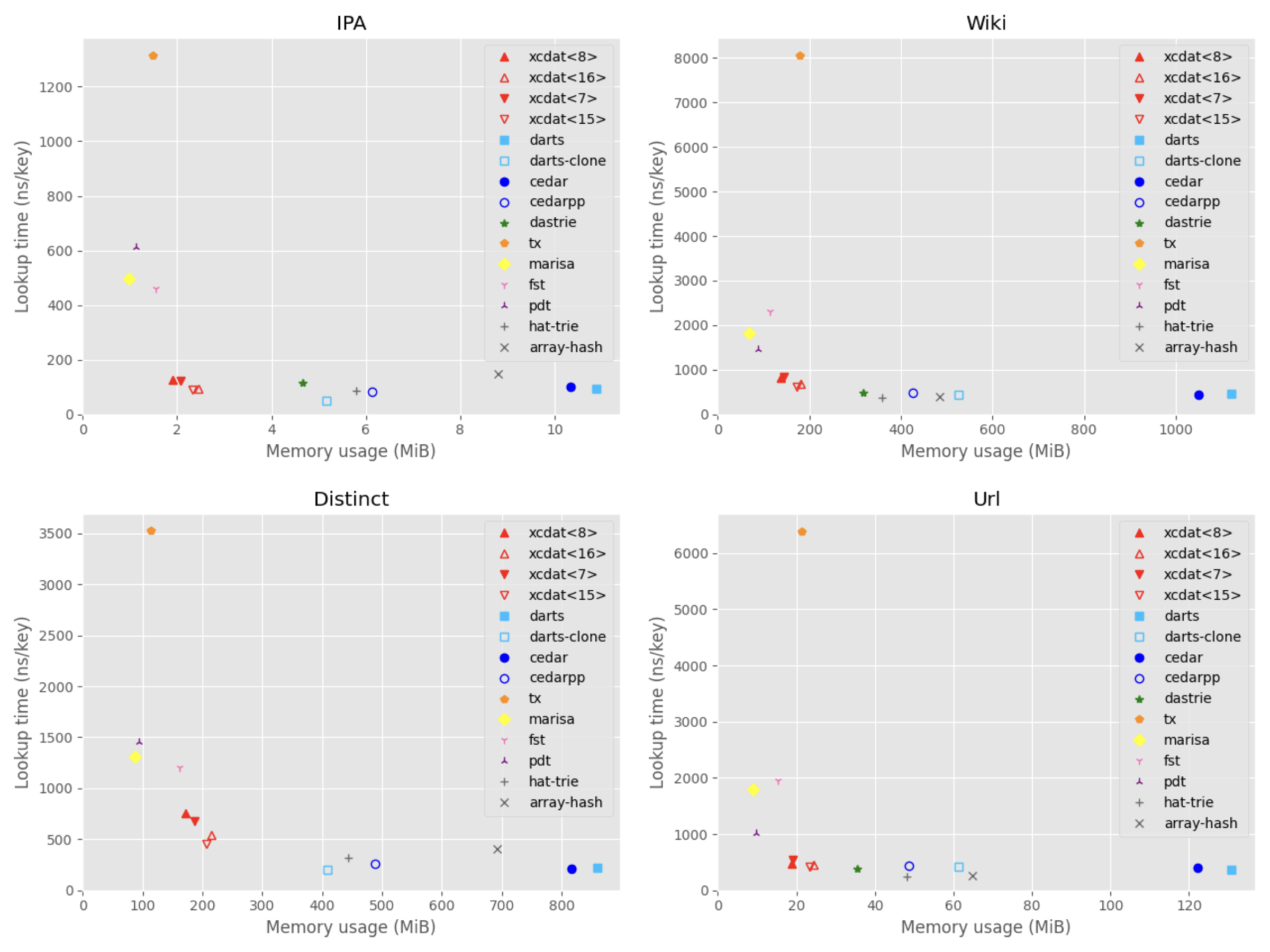
Plot: memory usage vs. lookup time
Plot: memory usage vs. build time
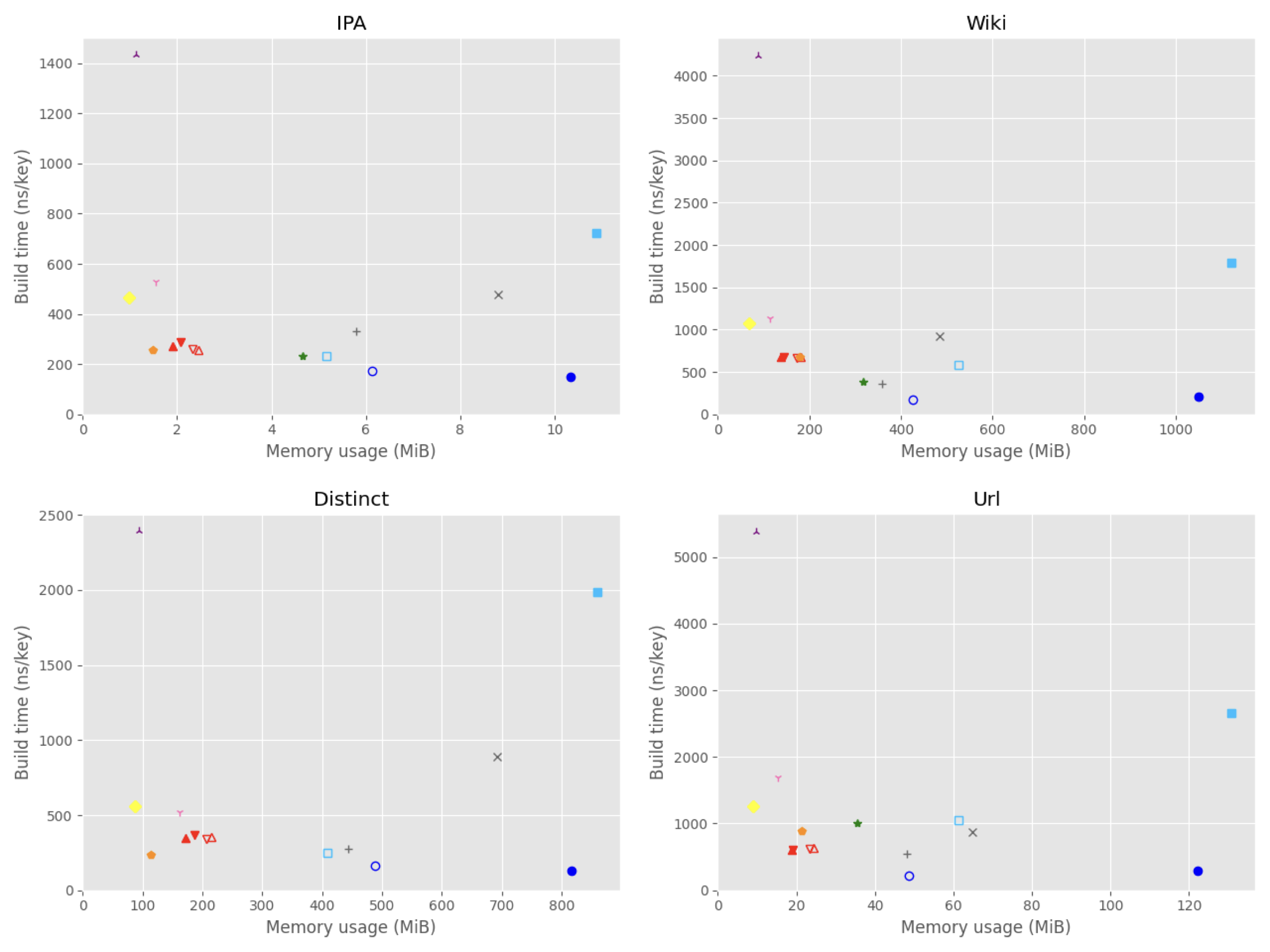
Table: IPA
| Library | Data structure | Memory (MiB) | Build (ns/key) | Lookup (ns/key) | Decode (ns/id) |
|---|---|---|---|---|---|
| xcdat<8> | XCDA prefix trie | 1.9 | 271 | 124 | 198 |
| xcdat<16> | XCDA prefix trie | 2.5 | 257 | 94 | 144 |
| xcdat<7> | XCDA prefix trie | 2.1 | 288 | 122 | 192 |
| xcdat<15> | XCDA prefix trie | 2.3 | 259 | 89 | 139 |
| darts | Double-array trie | 10.9 | 725 | 94 | n/a |
| darts-clone | Compact double-array trie | 5.2 | 231 | 52 | n/a |
| cedar | Double-array reduced trie (dyn) | 10.3 | 150 | 101 | n/a |
| cedarpp | Double-array prefix trie (dyn) | 6.1 | 171 | 83 | n/a |
| dastrie | Compact double-array prefix trie | 4.7 | 233 | 117 | n/a |
| tx | LOUDS trie | 1.5 | 256 | 1315 | 1289 |
| marisa | LOUDS nested patricia trie | 1.0 | 466 | 498 | 385 |
| fst | Fast succinct prefix trie | 1.6 | 529 | 460 | n/a |
| pdt | Centroid path-decomposed trie with RePair | 1.1 | 1436 | 614 | 716 |
| hat-trie | HAT-trie (dyn) | 5.8 | 330 | 87 | n/a |
| array-hash | Array hashing (dyn) | 8.8 | 476 | 147 | n/a |
Table: Wiki
| Library | Data structure | Memory (MiB) | Build (ns/key) | Lookup (ns/key) | Decode (ns/id) |
|---|---|---|---|---|---|
| xcdat<8> | XCDA prefix trie | 139 | 672 | 826 | 1173 |
| xcdat<16> | XCDA prefix trie | 182 | 672 | 679 | 902 |
| xcdat<7> | XCDA prefix trie | 144 | 674 | 829 | 1153 |
| xcdat<15> | XCDA prefix trie | 174 | 668 | 619 | 821 |
| darts | Double-array trie | 1121 | 1795 | 452 | n/a |
| darts-clone | Compact double-array trie | 525 | 584 | 450 | n/a |
| cedar | Dynamic double-array reduced trie | 1049 | 210 | 445 | n/a |
| cedarpp | Dynamic double-array prefix trie | 425 | 174 | 484 | n/a |
| dastrie | Compact double-array prefix trie | 317 | 387 | 488 | n/a |
| tx | LOUDS trie | 178 | 674 | 8062 | 7086 |
| marisa | LOUDS nested patricia trie | 69 | 1078 | 1818 | 1515 |
| fst | Fast succinct prefix trie | 114 | 1132 | 2309 | n/a |
| pdt | Centroid path-decomposed trie with RePair | 89 | 4242 | 1456 | 1514 |
| hat-trie | HAT-trie | 358 | 361 | 368 | n/a |
| array-hash | Array hashing | 484 | 927 | 385 | n/a |
Table: Distinct
| Library | Data structure | Memory (MiB) | Build (ns/key) | Lookup (ns/key) | Decode (ns/id) |
|---|---|---|---|---|---|
| xcdat<8> | XCDA prefix trie | 172 | 347 | 757 | 1017 |
| xcdat<16> | XCDA prefix trie | 215 | 357 | 543 | 742 |
| xcdat<7> | XCDA prefix trie | 186 | 371 | 676 | 1003 |
| xcdat<15> | XCDA prefix trie | 206 | 339 | 451 | 691 |
| darts | Double-array trie | 859 | 1990 | 225 | n/a |
| darts-clone | Compact double-array trie | 409 | 251 | 198 | n/a |
| cedar | Dynamic double-array reduced trie | 817 | 127 | 213 | n/a |
| cedarpp | Dynamic double-array prefix trie | 488 | 164 | 261 | n/a |
| tx | LOUDS trie | 113 | 233 | 3523 | 3147 |
| marisa | LOUDS nested patricia trie | 87 | 558 | 1311 | 1041 |
| fst | Fast succinct prefix trie | 161 | 519 | 1201 | n/a |
| pdt | Centroid path-decomposed trie with RePair | 94 | 2393 | 1453 | 1681 |
| hat-trie | HAT-trie | 443 | 275 | 322 | n/a |
| array-hash | Array hashing | 693 | 891 | 411 | n/a |
- I don’t know why, but dastrie did not complete the build.
Table: Url
| Library | Data structure | Memory (MiB) | Build (ns/key) | Lookup (ns/key) | Decode (ns/id) |
|---|---|---|---|---|---|
| xcdat<8> | XCDA prefix trie | 19 | 606 | 469 | 685 |
| xcdat<16> | XCDA prefix trie | 24 | 633 | 461 | 682 |
| xcdat<7> | XCDA prefix trie | 19 | 605 | 542 | 772 |
| xcdat<15> | XCDA prefix trie | 23 | 624 | 423 | 625 |
| darts | Double-array trie | 131 | 2659 | 366 | n/a |
| darts-clone | Compact double-array trie | 61 | 1045 | 411 | n/a |
| cedar | Dynamic double-array reduced trie | 122 | 287 | 403 | n/a |
| cedarpp | Dynamic double-array prefix trie | 49 | 220 | 442 | n/a |
| dastrie | Compact double-array prefix trie | 35 | 1009 | 381 | n/a |
| tx | LOUDS trie | 21 | 887 | 6389 | 6058 |
| marisa | LOUDS nested patricia trie | 9 | 1261 | 1789 | 1747 |
| fst | Fast succinct prefix trie | 15 | 1692 | 1948 | n/a |
| pdt | Centroid path-decomposed trie with RePair | 10 | 5385 | 1013 | 1287 |
| hat-trie | HAT-trie | 48 | 541 | 235 | n/a |
| array-hash | Array hashing | 65 | 868 | 268 | n/a |
Licensing
This library is free software provided under the MIT License.
If you use the library in academic settings, please cite the following paper.
@article{kanda2017compressed,
title={Compressed double-array tries for string dictionaries supporting fast lookup},
author={Kanda, Shunsuke and Morita, Kazuhiro and Fuketa, Masao},
journal={Knowledge and Information Systems (KAIS)},
volume={51},
number={3},
pages={1023--1042},
year={2017},
publisher={Springer}
}
Todo
- Support other language bindings.
- Add SIMD-ization.
References
- M. A. Martínez-Prieto, N. Brisaboa, R. Cánovas, F. Claude, and G. Navarro. Practical compressed string dictionaries. Information Systems, 56:73–108, 2016.
- S. Kanda, K. Morita, and M. Fuketa. Compressed double-array tries for string dictionaries supporting fast lookup. Knowledge and Information Systems, 51(3): 1023–1042, 2017.
- J. Aoe. An efficient digital search algorithm by using a double-array structure. IEEE Transactions on Software Engineering, 15(9): 1066–1077, 1989.
- S. Yata, M. Oono, K. Morita, M. Fuketa, T. Sumitomo, and J. Aoe. A compact static double-array keeping character codes. Information Processing & Management, 43(1): 237–247, 2007.
- I. Mülle, R. Cornelius, and F. Franz. Adaptive string dictionary compression in in-memory column-store database systems. In Proc. EDBT, pp. 283–294, 2014.
- S. Gog, GE. Pibiri, and R. Venturini. Efficient and effective query auto-completion. In Proc. SIGIR, pp. 2271–2280, 2020.
- R. Baeza-Yates, and B. Ribeiro-Neto. Modern Information Retrieval. 2nd ed. Addison Wesley, Boston, MA, USA, 2011.
- T. Kudo, T. Hanaoka, J. Mukai, Y. Tabata, and H. Komatsu. Efficient dictionary and language model compression for input method editors. In Proc. WTIM, pp. 19–25, 2011.
- N. R. Brisaboa, S. Ladra, and G. Navarro. DACs: Bringing direct access to variable-length codes. Information Processing & Management, 49(1): 392–404, 2013.
- S. Yata, M. Tamura, K. Morita, M. Fuketa and J. Aoe. Sequential insertions and performance evaluations for double-arrays. In Proc. IPSJ, pp. 1263–1264, 2009.
- N. Yoshinaga, and M. Kitsuregawa. A self-adaptive classifier for efficient text-stream processing. In Proc. COLING, pp. 1091–1102, 2014.
- G. Jacobson. Space-efficient static trees and graphs. In Proc. FOCS, pp. 549–554, 1989.
- S. Yata. Dictionary compression by nesting prefix/patricia tries. In Proc. JNLP, pp. 576–578, 2011.
- H. Zhang, H. Lim, V. Leis, DG. Andersen, M. Kaminsky, K. Keeton, and A. Pavlo. Surf: Practical range query filtering with fast succinct tries. In Proc. SIGMOD, pp. 323–336, 2018.
- R. Grossi, and G. Ottaviano. Fast compressed tries through path decompositions. ACM Journal of Experimental Algorithmics, 19, 2015.
- N. Askitis, and R. Sinha. Engineering scalable, cache and space efficient tries for strings. The VLDB Journal, 19(5): 633-660, 2010.
- N. Askitis, and J. Zobel. Cache-conscious collision resolution in string hash tables. In Proc. SPIRE, pp. 91–102, 2005.